To use all functions of this page, please activate cookies in your browser.
My watch list
my.chemeurope.com
my.chemeurope.com
With an accout for my.chemeurope.com you can always see everything at a glance – and you can configure your own website and individual newsletter.
- My watch list
- My saved searches
- My saved topics
- My newsletter
Primary structure
In biochemistry, the primary structure of a biological molecule is the exact specification of its atomic composition and the chemical bonds connecting those atoms (including stereochemistry). For a typical unbranched, un-crosslinked biopolymer (such as a molecule of DNA, RNA or typical intracellular protein), the primary structure is equivalent to specifying the sequence of its monomeric subunits, e.g., the nucleotide or peptide sequence. The term "primary structure" was first coined by Linderstrøm-Lang in his 1951 Lane Medical Lectures. Primary structure is sometimes mistakenly termed primary sequence, but there is no such term, as well as no parallel concept of secondary or tertiary sequence. Additional recommended knowledge
Primary structure of polypeptidesIn general, polypeptides are unbranched polymers, so their primary structure can often be specified by the sequence of amino acids along their backbone. However, proteins can become cross-linked, most commonly by disulfide bonds, and the primary structure also requires specifying the cross-linking atoms, e.g., specifying the cysteines involved in the protein's disulfide bonds. Other crosslinks include desmosine... The chiral centers of a polypeptide chain can undergo racemization. In particular, the L-amino acids normally found in proteins can spontaneously isomerize at the Cα atom to form D-amino acids, which cannot be cleaved by most proteases. Finally, the protein can undergo a variety of posttranslational modifications, which are briefly summarized here. The N-terminal amino group of a polypeptide can be modified covalently, e.g.,
The C-terminal carboxylate group of a polypeptide can also be modified, e.g.,
Finally, the peptide side chains can also be modified covalently, e.g.,
Tyrosines may become sulfated on their Oη atom. Somewhat unusually, this modification occurs in the Golgi apparatus, not in the endoplasmic reticulum. Similar to phosphorylated tyrosines, sulfated tyrosines are used for specific recognition, e.g., in chemokine receptors on the cell surface. As with phosphorylation, sulfation adds a negative charge to a previously neutral site.
The hydrophobic isoprene (e.g., farnesyl, geranyl, and geranylgeranyl groups) and palmitoyl groups may be added to the Sγ atom of cysteine residues to anchor proteins to cellular membranes. Unlike the GPI and myritoyl anchors, these groups are not necessarily added at the termini.
The large ADP-ribosyl group can be transferred to several types of side chains within proteins, with heterogeneous effects. This modification is a target for the powerful toxins of disparate bacteria, e.g., Vibrio cholerae, Corynebacterium diphtheriae and Bordetella pertussis. Various full-length, folded proteins can be attached at their C-termini to the sidechain ammonium groups of lysines of other proteins. Ubiquitin is the most common of these, and usually signals that the ubiquitin-tagged protein should be degraded. Most of the polypeptide modifications listed above occur post-translationally, i.e., after the protein has been synthesized on the ribosome, typically occurring in the endoplasmic reticulum, a subcellular organelle of the eukaryotic cell. Many other chemical reactions (e.g., cyanylation) have been applied to proteins by chemists, although they are not found in biological systems. Modifications of primary structureIn addition to those listed above, the most important modification of primary structure is peptide cleavage (See: Protease). Proteins are often synthesized in an inactive precursor form; typically, an N-terminal or C-terminal segment blocks the active site of the protein, inhibiting its function. The protein is activated by cleaving off the inhibitory peptide. Some proteins even have the power to cleave themselves. Typically, the hydroxyl group of a serine (rarely, threonine) or the thiol group of a cysteine residue will attack the carbonyl carbon of the preceding peptide bond, forming a tetrahedrally bonded intermediate [classified as a hydroxyoxazolidine (Ser/Thr) or hydroxythiazolidine (Cys) intermediate]. This intermediate tends to revert to the amide form, expelling the attacking group, since the amide form is usually favored by free energy, (presumably due to the strong resonance stabilization of the peptide group). However, additional molecular interactions may render the amide form less stable; the amino group is expelled instead, resulting in an ester (Ser/Thr) or thioester (Cys) bond in place of the peptide bond. This chemical reaction is called an N-O acyl shift. The ester/thioester bond can be resolved in several ways:
History of protein primary structureThe proposal that proteins were linear chains of α-amino acids was made nearly simultaneously by two scientists at the same conference in 1902, the 74th meeting of the Society of German Scientists and Physicians, held in Karlsbad. Franz Hofmeister made the proposal in the morning, based on his observations of the biuret reaction in proteins. Hofmeister was followed a few hours later by Emil Fischer, who had amased a wealth of chemical details supporting the peptide-bond model. For completeness, the proposal that proteins contained amide linkages was made as early as 1882 by the French chemist E. Grimaux. Despite these data and later evidence that proteolytically digested proteins yielded only oligopeptides, the idea that proteins were linear, unbranched polymers of amino acids was not accepted immediately. Some well-respected scientists such as William Astbury doubted that covalent bonds were strong enough to hold such long molecules together; they feared that thermal agitations would shake such long molecules asunder. Hermann Staudinger faced similar prejudices in the 1920s when he argued that rubber was composed of macromolecules. Thus, several alternative hypotheses arose. The colloidal protein hypothesis stated that proteins were colloidal assemblies of smaller molecules. This hypothesis was disproven in the 1920s by ultracentrifugation measurements by The Svedberg that showed that proteins had a well-defined, reproducible molecular weight and by electrophoretic measurements by Arne Tiselius that indicated that proteins were single molecules. A second hypothesis, the cyclol hypothesis advanced by Dorothy Wrinch, proposed that the linear polypeptide underwent a chemical cyclol rearrangement C=O + HN Relation to secondary and tertiary structureThe primary structure of a biological polymer to a large extent determines the three-dimensional shape known as the tertiary structure, but nucleic acid and protein folding are so complex that knowing the primary structure often doesn't help either to deduce the shape or to predict localized secondary structure, such as the formation of loops or helices. However, knowing the structure of a similar homologous sequence (for example a member of the same protein family) can unambiguously identify the tertiary structure of the given sequence. Sequence families are often determined by sequence clustering, and structural genomics projects aim to produce a set of representative structures to cover the sequence space of possible non-redundant sequences. Primary structure in other moleculesAny linear-chain heteropolymer can be said to have a "primary structure" by analogy to the usage of the term for proteins, but this usage is rare compared to the extremely common usage in reference to proteins. In RNA, which also has extensive secondary structure, the linear chain of bases is generally just referred to as the "sequence" as it is in DNA (which usually forms a linear double helix with little secondary structure). Other biological polymers such as polysaccharides can also be considered to have a primary structure, although the usage is not standard. See alsoReferences
|
|
| This article is licensed under the GNU Free Documentation License. It uses material from the Wikipedia article "Primary_structure". A list of authors is available in Wikipedia. |


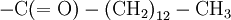
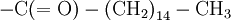
 C(OH)-N that crosslinked its backbone amide groups, forming a two-dimensional fabric. Other primary structures of proteins were proposed by various researchers, such as the diketopiperazine model of
C(OH)-N that crosslinked its backbone amide groups, forming a two-dimensional fabric. Other primary structures of proteins were proposed by various researchers, such as the diketopiperazine model of 

