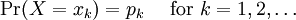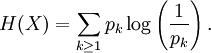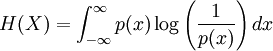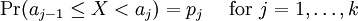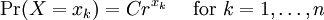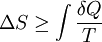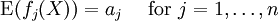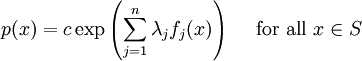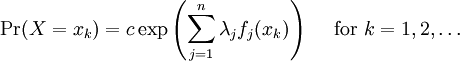To use all functions of this page, please activate cookies in your browser.
My watch list
my.chemeurope.com
my.chemeurope.com
With an accout for my.chemeurope.com you can always see everything at a glance – and you can configure your own website and individual newsletter.
- My watch list
- My saved searches
- My saved topics
- My newsletter
Maximum entropy probability distributionIn statistics and information theory, a maximum entropy probability distribution is a probability distribution whose entropy is at least as great as that of all other members of a specified class of distributions. If nothing is known about a distribution except that it belongs to a certain class, then the maximum entropy distribution for that class is often chosen as a default, according to the principle of maximum entropy. The motivation is twofold: first, maximizing entropy, in a sense, means minimizing the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time. Product highlight
Definition of entropyIf X is a discrete random variable with distribution given by then the entropy of X is defined as If X is a continuous random variable with probability density p(x), then the entropy of X is defined as where p(x) log(1/p(x)) is understood to be zero whenever p(x) = 0. The base of the logarithm is not important as long as the same one is used consistently: change of base merely results in a rescaling of the entropy. Information theoreticians may prefer to use base 2 in order to express the entropy in bits; mathematicians and physicists will often prefer the natural logarithm, resulting in a unit of nats or nepers for the entropy. Examples of maximum entropy distributionsGiven mean and standard deviation: the normal distributionThe normal distribution N(μ,σ2) has maximum entropy among all real-valued distributions with specified mean μ and standard deviation σ. Therefore, if all you know about a distribution is its mean and standard deviation, it is often reasonable to assume that the distribution is normal. Uniform and piecewise uniform distributionsThe uniform distribution on the interval [a,b] is the maximum entropy distribution among all continuous distributions which are supported in the interval [a, b] (which means that the probability density is 0 outside of the interval). More generally, if we're given a subdivision a=a0 < a1 < ... < ak = b of the interval [a,b] and probabilities p1,...,pk which add up to one, then we can consider the class of all continuous distributions such that The density of the maximum entropy distribution for this class is constant on each of the intervals [aj-1,aj); it looks somewhat like a histogram. The uniform distribution on the finite set {x1,...,xn} (which assigns a probability of 1/n to each of these values) is the maximum entropy distribution among all discrete distributions supported on this set. Positive and given mean: the exponential distributionThe exponential distribution with mean 1/λ is the maximum entropy distribution among all continuous distributions supported in [0,∞) that have a mean of 1/λ. In physics, this occurs when gravity acts on a gas that is kept at constant pressure and temperature: if X describes the height of a molecule, then the variable X is exponentially distributed (which also means that the density of the gas depends on height proportional to the exponential distribution). The reason: X is clearly positive and its mean, which corresponds to the average potential energy, is fixed. Over time, the system will attain its maximum entropy configuration, according to the second law of thermodynamics. Discrete distributions with given meanAmong all the discrete distributions supported on the set {x1,...,xn} with mean μ, the maximum entropy distribution has the following shape: where the positive constants C and r can be determined by the requirements that the sum of all the probabilities must be 1 and the expected value must be μ. For example, if a large number N of dice is thrown, and you are told that the sum of all the shown numbers is S. Based on this information alone, what would be a reasonable assumption for the number of dice showing 1, 2, ..., 6? This is an instance of the situation considered above, with {x1,...,x6} = {1,...,6} and μ = S/N. Finally, among all the discrete distributions supported on the infinite set {x1,x2,...} with mean μ, the maximum entropy distribution has the shape: where again the constants C and r can be determined by the requirements that the sum of all the probabilities must be 1 and the expected value must be μ. A theorem by BoltzmannAll the above examples are consequences of the following theorem by Boltzmann. Continuous versionSuppose S is a closed subset of the real numbers R and we're given n measurable functions f1,...,fn and n numbers a1,...,an. We consider the class C of all continuous random variables which are supported on S (i.e. whose density function is zero outside of S) and which satisfy the n expected value conditions If there is a member in C whose density function is positive everywhere in S, and if there exists a maximal entropy distribution for C, then its probability density p(x) has the following shape: where the constants c and λj have to be determined so that the integral of p(x) over S is 1 and the above conditions for the expected values are satisfied. Conversely, if constants c and λj like this can be found, then p(x) is indeed the density of the (unique) maximum entropy distribution for our class C. This theorem is proved with the calculus of variations and Lagrange multipliers. Discrete versionSuppose S = {x1,x2,...} is a (finite or infinite) discrete subset of the reals and we're given n functions f1,...,fn and n numbers a1,...,an. We consider the class C of all discrete random variables X which are supported on S and which satisfy the n conditions If there exists a member of C which assigns positive probability to all members of S and if there exists a maximum entropy distribution for C, then this distribution has the following shape: where the constants c and λj have to be determined so that the sum of the probabilities is 1 and the above conditions for the expected values are satisfied. Conversely, if constants c and λj like this can be found, then the above distribution is indeed the maximum entropy distribution for our class C. This version of the theorem can be proved with the tools of ordinary calculus and Lagrange multipliers. CaveatsNote that not all classes of distributions contain a maximum entropy distribution. It is possible that a class contain distributions of arbitrarily large entropy (e.g. the class of all continuous distributions on R with mean 0), or that the entropies are bounded above but there is no distribution which attains the maximal entropy (e.g. the class of all continuous distributions X on R with E(X) = 0 and E(X2) = E(X3) = 1). It is also possible that the expected value restrictions for the class C force the probability distribution to be zero in certain subsets of S. In that case our theorem doesn't apply, but one can work around this by shrinking the set S. References
Categories: Entropy and information | Particle statistics |
||||||||||||||||
| This article is licensed under the GNU Free Documentation License. It uses material from the Wikipedia article "Maximum_entropy_probability_distribution". A list of authors is available in Wikipedia. | ||||||||||||||||