To use all functions of this page, please activate cookies in your browser.
My watch list
my.chemeurope.com
my.chemeurope.com
With an accout for my.chemeurope.com you can always see everything at a glance – and you can configure your own website and individual newsletter.
- My watch list
- My saved searches
- My saved topics
- My newsletter
Cross-entropy methodThe cross-entropy (CE) method attributed to Reuven Rubinstein is a general Monte Carlo approach to combinatorial and continuous multi-extremal optimization and importance sampling. The method originated from the field of rare event simulation, where very small probabilities need to be accurately estimated, for example in network reliability analysis, queueing models, or performance analysis of telecommunication systems. The CE method can be applied to static and noisy combinatorial optimization problems such as the traveling salesman problem, the quadratic assignment problem, DNA sequence alignment, the max-cut problem and the buffer allocation problem, as well as continuous global optimization problems with many local extrema. In a nutshell the CE method consists of two phases:
Product highlight
Estimation via importance samplingConsider the general problem of estimating the quantity Generic CE algorithm
In several cases, the solution to step 3 can be found analytically. Situations in which this occurs are
Continuous optimization—exampleThe same CE algorithm can be used for optimization, rather than estimation.
Suppose the problem is to maximize some function S(x), for example,
Pseudo-code1. mu:=-6; sigma2:=100; t:=0; maxits=100; // Initialize parameters 2. N:=100; Ne:=10; // 3. while t < maxits and sigma2 > epsilon // While not converged and maxits not exceeded 4. X = SampleGaussian(mu,sigma2,N); // Obtain N samples from current sampling distribution 5. S = exp(-(X-2)^2) + 0.8 exp(-(X+2)^2); // Evaluate objective function at sampled points 6. X = sort(X,S); // Sort X by objective function values (in descending order) 7. mu = mean(X(1:Ne)); sigma2=var(X(1:Ne)); // Update parameters of sampling distribution 8. t = t+1; // Increment iteration counter 9. return mu // Return mean of final sampling distribution as solution Related methods
See also
References
|
|
| This article is licensed under the GNU Free Documentation License. It uses material from the Wikipedia article "Cross-entropy_method". A list of authors is available in Wikipedia. |



![\ell = \mathbb{E}_{\mathbf{u}}[H(\mathbf{X})] = \int H(\mathbf{x})\, f(\mathbf{x}; \mathbf{u})\, \textrm{d}\mathbf{x}](images/math/c/f/e/cfe21091f206aedf955e27057f89b955.png) , where
, where 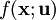 is a member of some parametric family of distributions. Using
is a member of some parametric family of distributions. Using 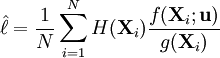 , where
, where 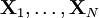 is a random sample from
is a random sample from 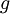 . For positive
. For positive 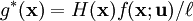 . This, however, depends on the unknown
. This, however, depends on the unknown 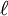 . The CE method aims to approximate the optimal pdf by adaptively selecting members of the parametric family that are closest (in the
. The CE method aims to approximate the optimal pdf by adaptively selecting members of the parametric family that are closest (in the 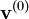 ; set t = 1.
; set t = 1.
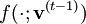
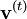 , where
, where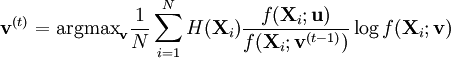
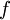 belongs to the natural exponential family
belongs to the natural exponential family
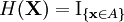 and
and 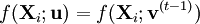 , then
, then 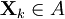 .
.
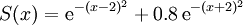 .
To apply CE, one considers first the associated stochastic problem of estimating
.
To apply CE, one considers first the associated stochastic problem of estimating
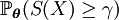 for a given level
for a given level 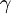 , and parametric family
, and parametric family 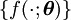 , for example the 1-dimensional
Gaussian distribution,
parameterized by its mean
, for example the 1-dimensional
Gaussian distribution,
parameterized by its mean 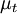 and variance
and variance 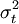 (so
(so 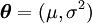 here).
Hence, for a given
here).
Hence, for a given 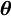 so that
so that
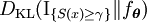 is minimized. This is done by solving the sample version (stochastic counterpart) of the KL divergence minimization problem, as in step 3 above.
It turns out that parameters that minimize the stochastic counterpart for this choice of target distribution and
parametric family are the sample mean and sample variance corresponding to the elite samples, which are those samples that have objective function value
is minimized. This is done by solving the sample version (stochastic counterpart) of the KL divergence minimization problem, as in step 3 above.
It turns out that parameters that minimize the stochastic counterpart for this choice of target distribution and
parametric family are the sample mean and sample variance corresponding to the elite samples, which are those samples that have objective function value 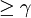 .
The worst of the elite samples is then used as the level parameter for the next iteration.
This yields the following randomized algorithm for this problem.
.
The worst of the elite samples is then used as the level parameter for the next iteration.
This yields the following randomized algorithm for this problem.