L'intelligence artificielle au service de la microscopie à super-résolution
Un nouveau modèle génératif calcule les images plus efficacement que les approches établies
Annonces



L'intelligence artificielle générative (IA) est peut-être mieux connue grâce à des applications de création de textes ou d'images telles que ChatGPT ou Stable Diffusion. Mais son utilité au-delà est démontrée dans des domaines scientifiques de plus en plus variés. Dans leurs récents travaux, qui seront présentés lors de la prochaine conférence internationale sur les représentations d'apprentissage (ICLR), des chercheurs du Center for Advanced Systems Understanding (CASUS) du Helmholtz-Zentrum Dresden-Rossendorf (HZDR), en collaboration avec des collègues de l'Imperial College London et de l'University College London, ont mis au point un nouvel algorithme libre appelé Conditional Variational Diffusion Model (CVDM). Basé sur l'IA générative, ce modèle améliore la qualité des images en les reconstruisant à partir d'éléments aléatoires. En outre, le CVDM est moins coûteux en termes de calcul que les modèles de diffusion établis, et il peut être facilement adapté à une variété d'applications.
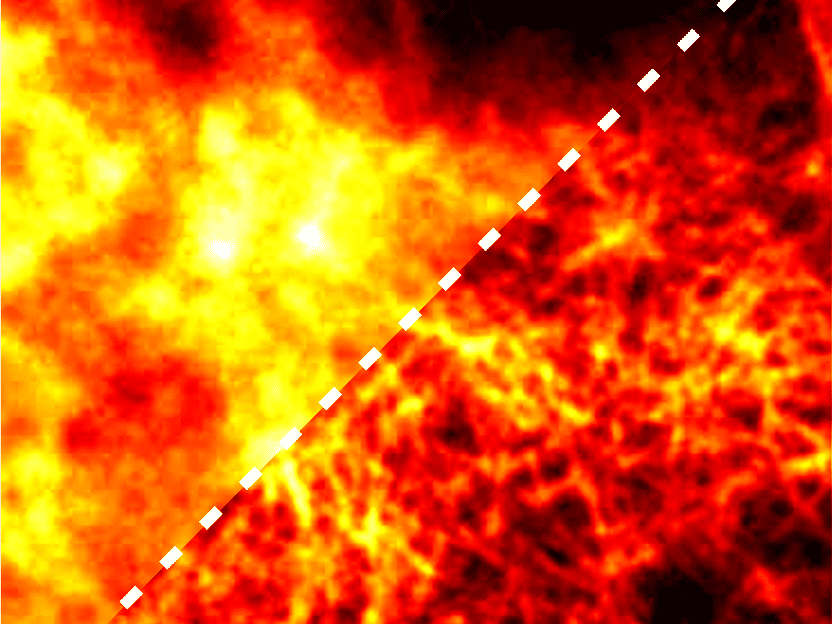
Micrographie de fluorescence extraite de l'ensemble de données de microscopie à super-résolution BioSR.
Source: A. Yakimovich/CASUS, modified image from the BioSR dataset by Chang Qiao & Di Li (licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/)
Avec l'avènement du big data et des nouvelles méthodes mathématiques et de science des données, les chercheurs cherchent à déchiffrer des phénomènes encore inexplicables en biologie, en médecine ou dans les sciences de l'environnement en utilisant des approches de problèmes inverses. Les problèmes inverses consistent à retrouver les facteurs de causalité à l'origine de certaines observations. Vous disposez d'une version en niveaux de gris d'une image et vous souhaitez récupérer les couleurs. Il existe généralement plusieurs solutions valables, car, par exemple, le bleu clair et le rouge clair sont identiques dans l'image en niveaux de gris. La solution à ce problème inverse peut donc être l'image avec le bleu clair ou celle avec la chemise rouge clair.
L'analyse d'images microscopiques peut également constituer un problème inverse typique. "Vous avez une observation : votre image microscopique. En appliquant certains calculs, vous pouvez en apprendre plus sur votre échantillon qu'il n'y paraît à première vue", explique Gabriel della Maggiora, doctorant à la CASUS et auteur principal de l'article de l'ICLR. Les résultats peuvent être des images de meilleure résolution ou de meilleure qualité. Cependant, le chemin entre les observations, c'est-à-dire les images microscopiques, et les "super images" n'est généralement pas évident. En outre, les données d'observation sont souvent bruitées, incomplètes ou incertaines. Tous ces éléments ajoutent à la complexité de la résolution des problèmes inverses, ce qui en fait des défis mathématiques passionnants.

La puissance des modèles d'IA générative comme Sora
L'un des outils les plus puissants pour résoudre les problèmes inverses est l'IA générative. Les modèles d'IA générative apprennent en général la distribution sous-jacente des données dans un ensemble de données d'apprentissage donné. Un exemple typique est la génération d'images. Après la phase d'apprentissage, les modèles d'IA générative génèrent des images entièrement nouvelles qui sont toutefois cohérentes avec les données d'apprentissage.
Parmi les différentes variantes de l'IA générative, une famille particulière, les modèles de diffusion, a récemment gagné en popularité auprès des chercheurs. Avec les modèles de diffusion, un processus itératif de génération de données démarre à partir d'un bruit de base, un concept utilisé dans la théorie de l'information pour imiter l'effet de nombreux processus aléatoires qui se produisent dans la nature. En ce qui concerne la génération d'images, les modèles de diffusion ont appris quels arrangements de pixels sont communs et peu communs dans les images de l'ensemble de données d'apprentissage. Ils génèrent la nouvelle image souhaitée bit par bit jusqu'à ce qu'une disposition de pixels coïncide le mieux avec la structure sous-jacente des données d'apprentissage. Un bon exemple de la puissance des modèles de diffusion est le modèle de conversion texte-vidéo Sora de l'éditeur américain de logiciels OpenAI. Un composant de diffusion implémenté permet à Sora de générer des vidéos qui semblent plus réalistes que tout ce que les modèles d'IA ont pu créer jusqu'à présent.
Mais il y a un inconvénient. "Les modèles de diffusion sont connus depuis longtemps pour leur coût de formation élevé. Certains chercheurs les ont récemment abandonnés pour cette raison", explique Artur Yakimovich, chef d'un groupe de jeunes chercheurs de la CASUS et auteur correspondant de l'article de l'ICLR. Mais de nouveaux développements, tels que notre modèle de diffusion variationnelle conditionnelle, permettent de minimiser les "exécutions improductives", qui n'aboutissent pas au modèle final. En réduisant l'effort de calcul et donc la consommation d'énergie, cette approche peut également rendre la formation des modèles de diffusion plus écologique".
L'entraînement intelligent fait ses preuves, et pas seulement dans le domaine du sport
Les "courses improductives" constituent un inconvénient majeur des modèles de diffusion. L'une des raisons est que le modèle est sensible au choix du programme prédéfini qui contrôle la dynamique du processus de diffusion : Ce calendrier régit la manière dont le bruit est ajouté : trop ou trop peu, au mauvais endroit ou au mauvais moment - il existe de nombreux scénarios possibles qui aboutissent à un échec de la formation. Jusqu'à présent, ce calendrier a été défini comme un hyperparamètre qui doit être ajusté pour chaque nouvelle application. En d'autres termes, lors de la conception du modèle, les chercheurs estiment généralement le calendrier qu'ils ont choisi par tâtonnement. Dans le nouvel article présenté à l'ICLR, les auteurs ont intégré le calendrier dès la phase d'apprentissage, de sorte que leur CVDM est capable de trouver l'apprentissage optimal par lui-même. Le modèle a alors donné de meilleurs résultats que d'autres modèles reposant sur un programme prédéfini.
Les auteurs ont notamment démontré l'applicabilité du CVDM à un problème scientifique : la microscopie à super-résolution, un problème inverse typique. La microscopie à super-résolution vise à surmonter la limite de diffraction, une limite qui restreint la résolution en raison des caractéristiques optiques du système microscopique. Pour surmonter cette limite sur le plan algorithmique, les scientifiques reconstruisent des images à plus haute résolution en éliminant à la fois le flou et le bruit des images enregistrées à résolution limitée. Dans ce scénario, le CVDM a donné des résultats comparables, voire supérieurs, à ceux des méthodes couramment utilisées.
"Bien entendu, il existe plusieurs méthodes permettant d'accroître la signification des images microscopiques, certaines d'entre elles reposant sur des modèles génératifs d'intelligence artificielle", explique M. Yakimovich. "Mais nous pensons que notre approche possède de nouvelles propriétés uniques qui auront un impact sur la communauté de l'imagerie, à savoir une grande flexibilité et une grande rapidité pour une qualité comparable, voire supérieure, à celle des autres approches basées sur des modèles de diffusion. En outre, notre CVDM fournit des indications directes en cas de doute sur la reconstruction - une propriété très utile qui ouvre la voie à la prise en compte de ces incertitudes dans de nouvelles expériences et simulations".
Gabriel della Maggiora présentera son travail sous forme de poster lors de la conférence internationale annuelle sur les représentations d'apprentissage (ICLR), le 8 mai, à la session de posters 3, à 10 h 45. Une courte présentation préenregistrée de l'article est disponible sur le site web. La conférence est organisée cette année pour la première fois depuis 2017 en Europe, à savoir à Vienne (Autriche). Que l'on y assiste sur place ou par vidéoconférence, un pass payant est nécessaire pour accéder au contenu. "L'ICLR utilise un processus d'évaluation par les pairs en double aveugle via le portail OpenReview", explique Yakimovich. "Les évaluations sont accompagnées de notes suggérées par les pairs ; seuls les articles ayant obtenu les meilleures notes sont acceptés. L'acceptation de notre article équivaut donc à une grande considération de la part de la communauté.
Note: Cet article a été traduit à l'aide d'un système informatique sans intervention humaine. LUMITOS propose ces traductions automatiques pour présenter un plus large éventail d'actualités. Comme cet article a été traduit avec traduction automatique, il est possible qu'il contienne des erreurs de vocabulaire, de syntaxe ou de grammaire. L'article original dans Anglais peut être trouvé ici.
Publication originale




Autres actualités du département science












































